

予測的符号化と音声理解
人間というのは言葉を使うことができますが、よくよく考えてみるとこの芸当は実に複雑にできています。
日本語だと標準的な速さで一秒間に6,7音(にほんごだと、ひょうじゅんてきな、などの発話が1秒)ですし、早口だと9,10音(にんげんというのは、ことばをつかうことが、などの発話が1秒)もの密度で話されており、
私達の脳は分けなくこういった唇から断続的に出される呼吸音を理解しているのですが、なぜこういった芸当ができるのでしょうか。
今回取り上げるのは音声理解についての脳機能についての総説論文になります。
Cortical oscillations and sensory predictions
この論文のキーとなっているのが、予測的符号化という概念なのですが、これはどのようなものなのでしょうか。
予測的符号化とは?
音声に限らず、私達が日々接する情報は莫大なのですが、私達の脳は難なくそれらの情報をうまく拾い上げています。
なぜこういった事ができるかというと、脳は何かを近くするに当たり事前に予測を立てているからではないかといことが近年考えられています。
教科書にかいてあるような考え方だと
刺激入力→脳の中で低次領域から高次領域に向かって逐次情報処理→認識・理解
というような流れだったのですが、最近出された予測符号化モデルだと
過去の経験に基づいてもっともありそうな情報を脳の中で構築→予想と現実の違いを検出→違いがあれば修正
というような仕組みで動いているのではないかということが考えられています。
私達の脳は、今まで生きてきた経験に基づいて、見たいように見て聞きたいように聞くようにできているということかと思います。
しかしながら、このような仕組みは音声理解においてどのように実装されているのでしょうか。
音声理解への実装
言葉の進化の起源を鳥の歌にもってくる研究もありますが、たしかに歌と話し言葉というのは似ています。
ともに音声も歌もリズムと言葉の組み合わせから出てきており、私達は脳は無意識的にこの2つの情報を拾い上げています。
このスピードであれば、このタイミングで次の言葉が出てくるだろう、この音の連なりはこのまま1秒くらい続くだろうということを無意識のうちに類推しながら言葉を聞いています。
そして言葉の連なりにもある程度のルールがあります。
「これまで述べたように・・・」であれば、次に来るのは「今までは・・」、「私達は・・」などという言葉が次に出てくるのかなとある程度類推できます。
私達の脳は今まで取り込んだ膨大なデータと、今置かれている状況(文脈)の2つを利用して、どのタイミングでどの言葉が出てくるか、常に一瞬先の言葉を予想しながら聞き耳を立てています。
この論文では過去に行われた神経生理学的研究から
音声のタイミングでの予期的な理解については、脳の中でも比較的ゆっくりとした脳波(デルタ波やシータ波)が、
言葉そのものの予期的な理解については比較的速い脳波が(ベータ波やガンマ波)が関わっていることを示しています。
言葉については、まず脳の中にデータベースを作るべく量を聞き取ったりするのが大事なのかと思ったり、
あるいは海外に出て数日取るのは、データベース(蓄積量)がそれほど変わらずとも、予測するシステムそのものがうまく回るためなのかなと思ったり、
さらにあるいは学習やリハビリテーションの現場では、この両方(データの蓄積とデータの運用)に対するアプローチが大事なのかなと思いました。
見ることと不思議:予測的符号化と視覚情報処理
私達は日々色んなものを見ています。それは目の前の患者さんの顔だったり、スマートフォンに映るこの文章だったりしますが、
なぜこのような白と黒のコントラストのシミのような模様を超高速で処理できるのでしょうか。
今回取り上げる論文は視覚的理解がどのような仕組みでなされているかについて、予測的符号化という仕組みで説明したものになります。
予測的符号化と視覚情報処理
予測的符号化というのは聞き慣れない言葉ですが、英語で書けばpredictive coding(プレディクティング コーディング)であり
このコーディングというのは、バーコードのコードとかと一緒で情報を記号化(符号化)することになります。
私達に脳はよくできているので、ついつい世界は私達が感じたまんま、見たまんまと思ってしがいがちですが、
実際世界にあるのは無数の光や音といった物理情報があるだけで、いろんな生き物は使い勝手がいいようにそれぞれ勝手に加工処理します。
コウモリは音波を使って世界を認識しますし、空を渡る渡り鳥はひょっとしたら地磁気を空に見ているかもしれません。
このようにいろんな生物は各々勝手に物理的な世界を使い勝手が良いように脳の中で編集加工しているのですが、
それは人間も一緒で見るもの、聞くものをリーズナブルかなたちで符号化します(この周波数は赤、この周波数は緑色というように)。
こうした世界の符号化に際して脳がどのように働くかという話なのですが、
この予測的符号化理論では、脳は今までの経験や直前の経験をもとに、実際に情報が入ってくる前に世界を符号化することが考えられています。
これがどういうことかというと、夕焼け空を見ているときであれば、いままでの経験から視界が徐々に暗くなってくることが分かっています。
またどれくらいの速さで暗くなるかということも、今までの経験からだいたい推測できます。
こういった経験則と現在置かれた状況を重ねて考えれば10分後どれくらい暗くなっているか(そろそろ暗くなるからお家へ帰ろう)というのは大体想像できるはずです。
10分後であればだいぶ意識的な処理ににはなりますが、脳というのはこれを1秒未満の短いスパンでどんどん前倒し的に予想を立てていき、
もし予想があってれば予想モデルはそのままで、もし間違っていたら予想と現実の誤差をもとにあらたに予想モデルを組み立て直します。
ではこれが具体的な視覚情報処理の仕組みで実装されるとしたらどういった仕組みになるのでしょうか。
視覚野における予測的符号化
一般に視覚野では低次の視覚野から高次の視覚野似情報が受け渡されていくことが知られています。
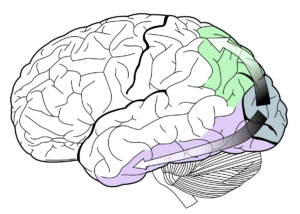
ところが実際にはこの情報の流れは一方向的なものでなく
一次視覚野と二次視覚野の関係で言えば、一次視覚野から二次視覚野へ向かう神経線維と、二次視覚野から一次視覚野に向かう神経線維は同じくらいあると言われています。
つまり双方向性の流れがあり、決して上の図のような一方向だけの流れではないことが解剖学的に分かっています。
では二次視覚野から一次視覚野への経路ではどのようなことが起こっているのでしょうか。
この論文によると、二次視覚野は一次視覚野の反応の仕方を調整しているのではないかということが述べられています。
一次視覚野は長さや傾き、色など様々な情報に対してそれぞれ選択的に働く神経細胞があることが知られています(斜め45度の直線だけに選択的に反応する神経細胞や黒色だけに反応する神経細胞など)。
二次視覚野は今までの経験と、直前の情報をもとに次の瞬間起こりそうな視覚情報が構成されるよう、一次視覚野の働きを調整します。
誰かの顔を見ていることを考えれば、通常目の前の顔の輪郭は次の瞬間も概ね同じなので、顔の輪郭情報をそうなるように一次視覚野に特定の色や傾きに反応する神経細胞の活動が起こるよう調整をします。
しかし何かの間違いで顔が急激に膨れたり、爆発したりしたような場合には、一次視覚野はその予測と実際の誤差を二次視覚野へ送り返します。
出典;北斗の拳 コミックス第2巻より

こういった誤差情報を送る手続きによって更に次の瞬間は正確に対象を認識することができます。
少しわかりにくいとは思いますが、ごくごく端的に言うと
予測する→予測通りになるように反応する→予測と違ってたら予測を修正→もっと正確に予測できるようになる
という流れで、私達は視覚認識しているのではないかということが、実際の数理モデルをもとにシミュレーションした結果を添えて示されています。

終わりに
ものを見るには体を介してものと接したり、ものと関わったりする経験が重要で、こういった学習なしではものを適切に見られないことが知られています。
また先天性の白内障の手術でも、手術終了直後はものがものとして認識できないことも知られています。
上の図はWikipediaから引っ張ってきた錯視図ですが、私達の目は目と体を介して構築されたデータベースをもとに
バイアスをかけて物事を見ているのかなと思いました。
赤ちゃんや子供が過剰なくらい外部世界と交流するのは(落ち着きなく飛んだりはねたり振り回したりして遊び回るのは)、脳を鍛えて、使い勝手の良い予測モデルを作り上げていく上でそれなりに理にかなっているのかなと思います。
脳科学に関するリサーチ・コンサルティングを承っております。
子育てや家事、臨床業務で時間のない研究者の方、
マーケティングや製品開発に必要な脳科学に関する論文を探している方、
数万円からの価格で資料収集・レポート作成をいたします!
ご興味のある方は以下よりどうぞ!
エラー: コンタクトフォームが見つかりません。