









目次
なぜすべての人は失敗するのか?
失敗がいいか悪いかというと、失敗自体は決して悪いことではないと思います。
というのも、ヒトは失敗なくしては何も学ぶことができないからです。
とはいえこの世は諸行無常、失敗を通して成長したあなたもいずれは勝負に勝てなくなります。
失敗を通してヒトは学べるにも関わらず、なぜヒトは老いて経験の少ない若手に負けてしまうのでしょうか。
この記事では、意思決定のメカニズムについて脳科学とロボティクスの見地から説いた論文について解説をします。
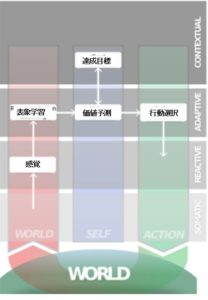
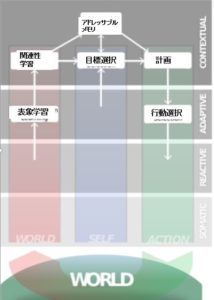
意思決定のメカニズム:反応的自己、適応的自己、文脈的自己
以前の記事で意思決定に関わるメカニズムというものを一つ紹介しましたが、
私達が意思決定するときには、3つのレベルがあるということでした。
一つは反応的自己で、これはカメレオンが視界に虫が入ると舌を反射的に伸ばすような自己になります。
もう一つは適応的自己で、寒い時にストーブに暖かさを感じてそこから離れないような、知覚と価値に基づいて動くような自己になります。
もう一つは文脈的自己というもので、意思決定に時間の流れが加味したようなものになります。
今日だけは自分へのご褒美で贅沢をする、子供の将来の学費のために出費を抑える、将来の成長のために思い切って自己投資するなどです。
これをモデル化すると、以下の図のようになるのですが、

これについて、すこし細かく見ていきたいと思います。
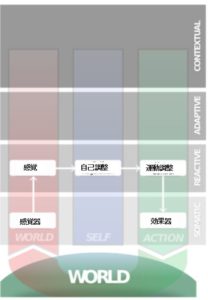
反応的自己におけるアロスタティックコントロール
ホメオスタシスというのはよく聞く言葉ですが、これと似たもので聞き慣れないものにアロスタシスという概念があります。
ホメオスタシスというのは、体温や血圧が一定に保たれるような仕組みで、上がりすぎれば下がる、下がりすぎれば上がるというように常に一定の範囲に体の状態を保つような仕組みになります。
これとは別にアロスタシスというものがあります。
これは体の基準状態そのものを状態に応じて変えるような仕組みになります。
分かりやすい例えで言えば休日モードと平日モードというものがあります。
休みボケとも言いますが、休日には急き立てられる仕事もないので、副交感神経が優位になってそれが基準となります。
休みが明けて会社に行くと、交感神経が優位になってそれが一定の基準で保たれるような平日モードになります。
つまりアロスタシスというのは、置かれた状況に応じて最適な基準状態になるように調整するような仕組みになります。
反応的自己にはこのアロスタシスの調整機構が含まれています。
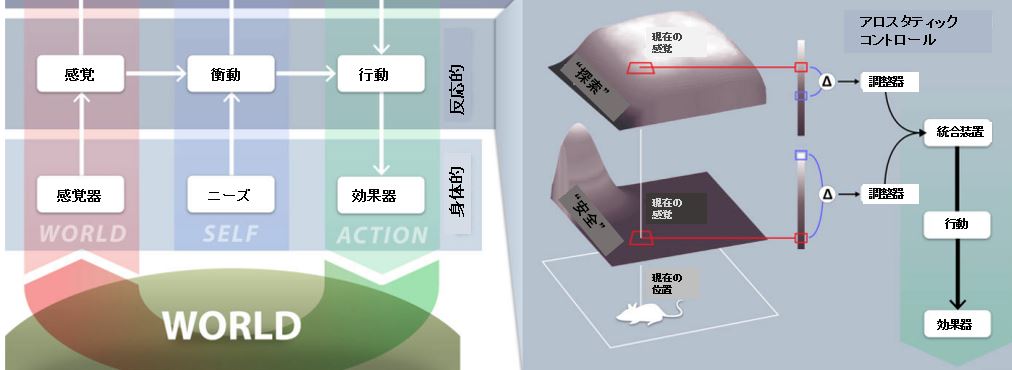
右の図でねずみがいるところを見てみましょう。
もし、ネズミが安全第一の安全モードでいるとして、このネズミが広い体育館の中ほどに置かれているとしましょう。
もし安全モードでいるのであれば、もっとも安全な場所は体育館の隅っこということになります。
とはいえ、そこまで行くには見知らぬ広い空間を走り抜けなけれればならず、コストは非常に高いものとなります(図中で示される高さはコストだと思ってください)。
ところがもしこのネズミが冒険モードにいるなら隅っこの価値は低くなり、むしろ置かれている体育館の中央部の価値が高くなります。この場合、冒険モードにいるネズミの欲求を満たすコストは非常に低くなります(図の⊿の大きさが欲求を満たすコスト)。
アロスタシスでは、このコストが最小化できるよう、個体の基準状態を調整します。
火事場のクソ力でもないのですが、置かれた状態に応じてもっとも最適な基準状態になるように調整する機構がアロスタティックコントロールであり、これは反応的自己のシステムの中に含まれます。
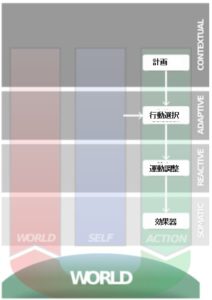
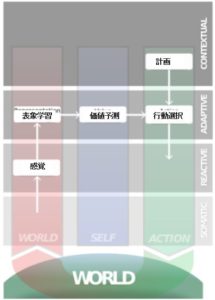
文脈的自己:経験に基づく判断とその仕組み
さて、文脈的自己というのは何かを決定する時に、時間の流れが加味されるようなものなのですが、これはどのようなものなのでしょうか。
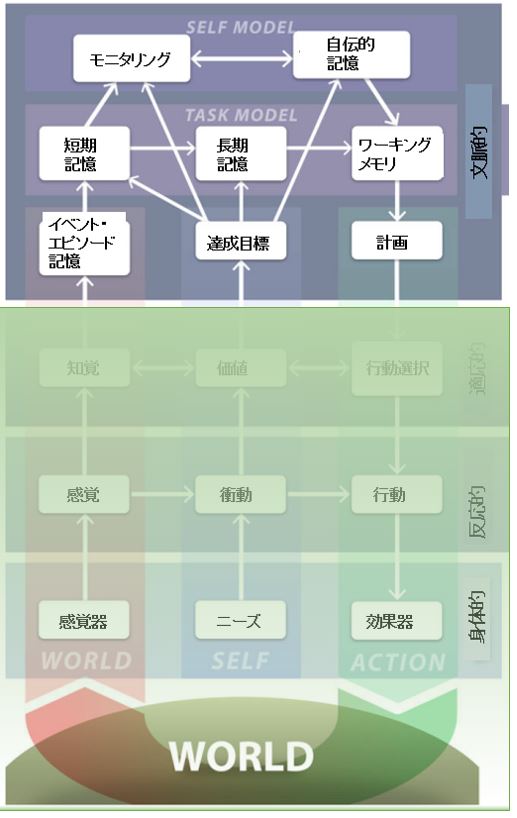
私達の身体は様々なものを知覚しますが、世界の情報は感覚器を通じて脳に届けられ、それはある種のイベント、出来事として記憶されます。
この記憶は脳の中で短期記憶として処理され、長期記憶に受け渡され、さらにワーキングメモリを経て、アウトプットされるような計画に仕立てられるのですが、ここを少し詳しく見てみましょう。
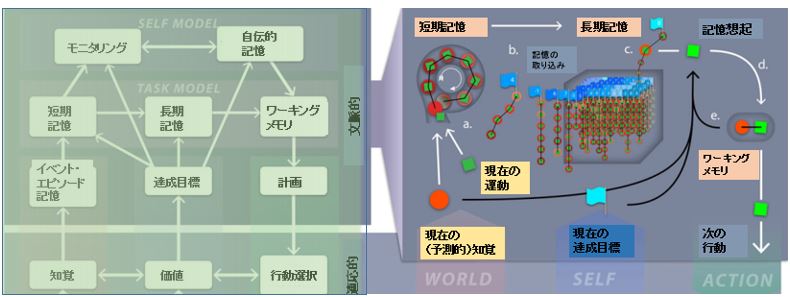
例えばテニスでボールを打ち返す練習をしていることを考えましょう。
こちらに飛んでくるボールはあまりにも早くてとても打ち返すことができないのですが、
それでも走り回ってラケットを振っていると、こんな時に(予測的知覚)こんなふうに動くと(現在の運動)、打ち返せる(達成目標)というのが分かってきます。
うまく行ったときの知覚と運動は短期記憶として組み合わせられ、
ゴールが達成できた、すなわち打ち返せたような時にはこの短期記憶はゴールに紐付けられて長期記憶として蓄えられます。
図を見ると一つのゴール(青い旗)にいくつかの短期記憶がぶら下げられていますが、
これは一つのゴール(例として相手の右コーナーに打ち返す)を達成できるパターンがいろいろあると考えてください。
このような経験を積んで様々な長期記憶が脳の中に蓄えられますが、
いざ本番の試合で「相手の右コーナーに打ち返そう!(ゴール)」と思っている時に、ある種の速さと軌道でボールが飛んできたときには(予測的知覚)、
脳は即座に長期記憶の中から、右コーナーに打ち返せたときに紐付けられた記憶の紐の中から、その時の予測的知覚と合致する記憶(感覚と運動がペアになったもの)とピックアップしてワーキングメモリに引っ張ってきて、ベストな運動をチョイスします。
私達はテニスに限らず、いろんなシチュエーションでいろんなアクションをして、うまく行ったり行かなかったりしますが、
これらのシチュエーションとアクションとその結果の組み合わせが長期記憶として蓄えられ、
あるシチュエーションである結果を出したい時に、ベストなアクションを行えるように作動してくれます。
私達は経験を重ねることでベストな行動を取ることができますが、こういった行動選択の肝になるのは様々な試行錯誤で出来上がった長期記憶の束がどれだけあるか、あるいはどれだけ長いかということになります。
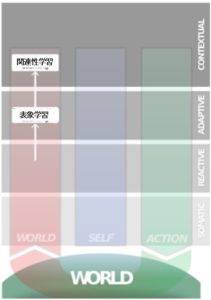
自伝的自己とワーキングメモリの関係
とはいえ、私達人間は社会的な動物であり、様々な場面での意思決定はもう少し複雑になります。
職人さんであれば、あまりに簡単な仕事は自分のレベルに合わないからやらないという意思決定もありますし、
あるいは困っている人がいたら割に合わなくても手伝ってあげるという意思決定もあります。
こういった意思決定は果たしてどのような仕組みでなされているのでしょうか。
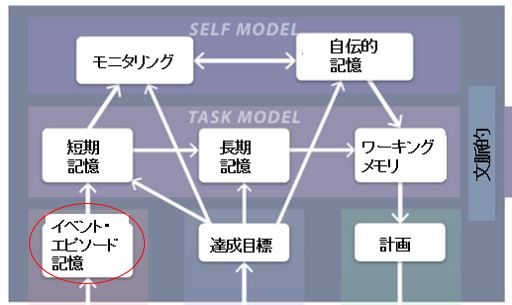
図を見てもらえば分かるのですが、ワーキングメモリの上位に自伝的記憶というものがあります。
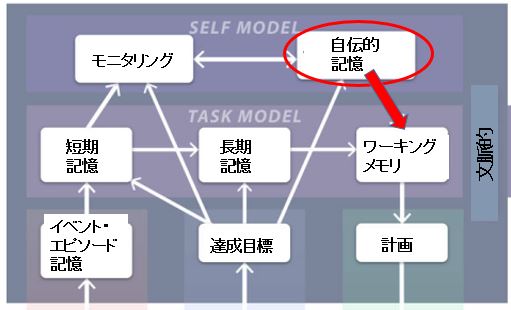
この自伝的記憶がワーキングメモリを調整しているのが図で示されていますが、これはどのような調整の仕方なのでしょうか。
これを端的に言うと、あなたがなにものかという意識がワーキングメモリの各要素に重み付けをするようなものになります。
休みの日に何かをしようとふと思うとき(ワーキングメモリ)、いろんな考えがよぎります。
山へ行こう、レストランへ行こう、勉強会へ行こう、家族をもてなそう、会社へ行こうなどいろいろですが、
その中でもベストだと思うものを選ぶはずです。
ではその基準は何でしょうか。
まず一つは確からしさということです。営業しているかいないか分からないようなレストランに行くのは少しはばかられますし、
あの店に行けば必ず営業していて、あのマスターがいて定番のあれが食べれると分かっていたらモチベーションは高まります。
もう一つは価値でしょう。
単身赴任していて久しぶりに過ごす家族の時間であれば、休みの日に家族と過ごすというのは価値は高くなりますが、これが毎日自宅にいて一人の時間がないというのであれば、週末家族と過ごす時間の価値は低くなります。
さらにもう一つはコストでしょう。どこか遠くへ旅行へ行きたいと思っていても、旅費が高かったり、移動時間が長かったりすると、モチベーションも少なくなってしまいます。
確実性、価値、コスト、これらの要素をその時のタイミングで様々に重み付けして私達はベストな選択を決定しますが、ここに介入してくるのが自伝的記憶、つまり今まで自分はどう生きてきて、これからどう生きていくのかという記憶の堆積です。
小さい頃、親に週末遊んでもらった記憶があれば、自分も週末は家族と過ごすかもしれませんし、
自分は仕事一筋で生きてきたし、これからもそう生きていくと思っていれば、週末も会社へでかけてしまうかもしれません。
時にはヒトはコスト無視、確実性無視、価値無視といった理不尽な選択をすることもありますが、それは彼/彼女の生きてきた歴史を反映した重み付けであり、人は様々な意思決定をとりうるということになります。
このようにヒトの意思決定には複雑な階層を介しているというモデルを紹介したのですが、もしこれを機械に実装させるとしたらどのようなものが考えられるのでしょうか。
人工知能の意思決定システム
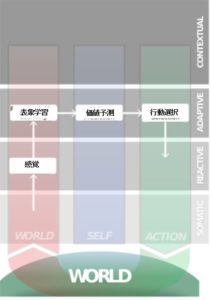
上に紹介したシステムは、分散的適応的コントロール(Distributed Adaptive Control:DAC)と呼ばれるものなのですが、これをコンピュータに実装させるとどのような形になるのでしょうか。
人工知能そのものは60年以上の歴史があり、その過程で様々なタイプのものが作られてきましたが、これを上記のシステムに当てはめたものをいくつか紹介します。
下の図に取り上げたのは初期に開発されたような仕組みで「行動基盤型ロボット(behavior-based robotics)」になります。部屋の中を走り回る自動掃除機がそれにあたります。
![]()
引用元:マイナビおすすめナビ【安くて高性能】ロボット掃除機おすすめ11選|静音設計やコンパクトタイプも

こちらはいわゆるトップダウン型ロボティクスと呼ばれるもので、工業機械にみられるような設計になります。
![]()
引用元:GLABCAD BLOG: The Top Industrial Robotic Arms from the GrabCAD Community

近年開発されて話題になった強化学習を通じて何が好ましい行動かを学習するDeep Q-Learningは「価値」そのものを学習できるようになっていますし、
![]()
引用元:IT media NEWS: Googleの人工知能「DQN」、アタリゲームで人間よりハイスコア叩き出す
さらにこのDeep Q-Learningに内発的報酬を実装した設計では、単に点数を最大化するだけでなく、自分の欲求を最大化するようにプログラムされます。
![]()
引用元:Playing Montezuma’s Revenge with Intrinsic Motivation

また大局観を持つAlphaGoは文脈に沿った計画ができるようになり
![]()
引用元:AI media: 最強囲碁AI「AlphaGo」が世界最強棋士に勝利 第1局

さらに人間は少ない経験でうまく予測を立てられるようになってきますが、これを確率論的手法で実装したBayesian Program Learningというものが開発され、
![]()
引用元:WirelessWire News:膨大なデータ処理が不要 – 人間のように学習する新たなAI技術
さらに人間の学習能力には、野球ができるようになるとソフトボールもできるようになり、ひいてはチームプレイそのものが得意になるという学習の汎化と呼ばれるようなものがありますが、
状況に応じて暗黙知のようなものを引き出してきて実行するような Differentiable Neural Computerというものも開発されています。
![]()
引用元:Slide share :Advanced Deep Architectures (D2L6 Deep Learning for Speech and Language UPC 2017)
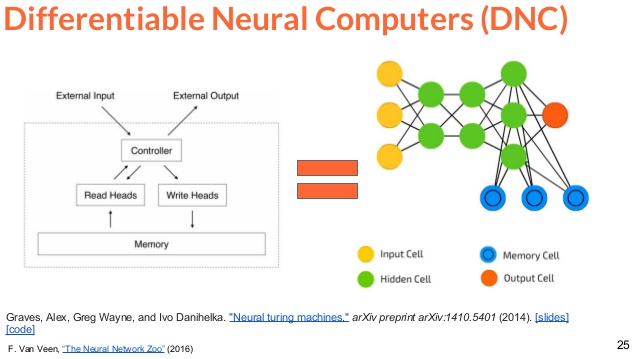
※余談ですが、添付図のネットワーク図、黄色を視覚野、緑を頭頂葉、青を側頭葉、赤を運動野と見立てるとヒトのものとよく似たシステムですね。
このように、人間の意思決定システムは高層、多層、並列的ですが、近年これを実装した人工知能が開発されてきています。
意思決定の洗練と成長の罠:なぜベテランが若手に負けるのか?
さて人間は人工知能でもないのですが、様々な経験を通して学習していきます。
例えばあなたがある業界に入ったとしましょう。
その業界の中での成功体験は長期記憶として蓄えられ、さらにこれらの経験は、自伝的記憶、すなわち自分はなにものかという意識を作り上げていきます。
意思決定をするに当たり、ワーキングメモリは、確実性と価値とコストというものを参考にしますが、
「わたしはなにものか」という自伝的記憶は、確実性と価値とコストに独特の重み付けをして、「わたし」らしく振る舞いまえるよう調整します。
ある業界での経験を重ねることで、あなたはその業界で勝てる方法を身につけ、そのような経験を通じてあなたは業界人はかくあるべしというアイデンティティ(自伝的自己)を獲得します。
こうして獲得した自伝的自己は、ワーキングメモリの重み付けを最適に行い、勝率もどんどん上がっていきます。
この流れで行けば、ベテランは決して若手に負けることはないはずなのですが、なぜ往々にしてベテランや老舗企業は新興企業に負けてしまうのでしょうか。
それはおそらくアイデンティティは変わり難いのに対して、環境は変わるときにはがらりと変わってしまうからでしょう。
アイデンティティ(自伝的記憶)はある環境での勝率を最大化するための装置です。
しかし環境が変わってしまえば「わたしらしい」重み付けは勝率を下げることもあるはずです。
環境が強固なアイデンティティを作りますが、アイデンティティを作ったはずの環境は節操がありません。
強固なアイデンティティは環境が変わらなければ有用ですが、環境が変われば足かせになってしまいます。
そのため、全てのヒトは長生きすれば必ず敗者となり、統計上明らかなように、ほぼ全ての企業は遅かれ早かれ消滅します。
身も蓋もないような話なのですが、システム全体で見れば新陳代謝があることは悪いことではないかとも思います。
まとめ
このように意思決定というのは多層的、階層的、並列的であると考えられており、近年はこれを実装した人工知能も開発されてきています。
ヒトは経験を通じて自伝的自己を形成し、そのことである環境での勝率を上げることができますが、環境が変われば自己そのものの改変も迫られます。
生き残ることに重きをおくのであれば、アイデンティティは軽々しく扱ったほうがいいのかなと思いました。
【参考文献】
脳科学に関するリサーチ・コンサルティングを承っております。
子育てや臨床業務で時間のない研究者の方、
マーケティングに必要なエビデンスを探している方、
数万円からの価格で資料収集・レポート作成をいたします!
ご興味のある方は以下よりどうぞ!






